subscribe via RSS
-
A cloud-native platform for push APIs
Apr 27, 2021 • posted by justin
 • filed under api, grip, pushpin, realtime, scalability, websockets
• filed under api, grip, pushpin, realtime, scalability, websocketsToday we are excited to announce Fanout Platform!
Fanout Platform is infrastructure software for building HTTP streaming and WebSocket APIs. It is comprised of our open source project, Pushpin, along with special add-ons for scaling. Helm charts are available for installation on Kubernetes.
Here’s a short video that shows how easy it is to upgrade from Pushpin to Fanout Platform:
Read on to learn about why we are doing this, and how it works.
-
Vercel and WebSockets
Sep 21, 2020 • posted by justin
• filed under api, faas, grip, realtime, websocketsVercel makes it easy to deploy and scale HTTP APIs using Serverless Functions. However, it’s not possible to use serverless functions to host WebSocket APIs. Does this mean you need to give up on your hopes and dreams and set up normal servers to handle your WebSockets? No way! Vercel can be combined with Fanout Cloud to handle WebSocket connections without having to literally host them.

By using Vercel and Fanout Cloud together, API logic can be kept in one place. Fanout Cloud can manage the WebSocket connections, and invoke functions whenever there is client activity. What’s great about this approach is there’s nothing extra to deploy, and it works at high scale too.
-
Let's Encrypt for custom domains
Sep 23, 2019 • posted by justin
• filed under api, fanout, security, usabilityToday we announce support for free and automatic SSL certificates provided by Let’s Encrypt in Fanout Cloud. To use this feature, simply edit your custom domain in the Fanout control panel and enable “Use Let’s Encrypt for SSL”. Assuming you have a proper CNAME record set up for your custom domain, a certificate will be created and installed within a few minutes.
-
Long-lived connections in a serverless world
Feb 15, 2019 • posted by justin
• filed under api, faas, fanout, grip, protocols, realtime, websocketsIn serverless architectures, application logic is often powered by short-lived execution environments. But what does this mean for long-lived connections? After all, many applications today depend on persistent WebSocket or SSE connections in order to exchange data in realtime.
The answer is unsurprising: either the execution limitations must be tolerated, or long-lived connections must be handled by a separate component. We’ll go over these approaches below.
-
Goodbye, XMPP
May 18, 2018 • posted by justin
• filed under api, fanout, protocols, realtime, xmppToday we removed support for XMPP in Fanout Cloud.
Fanout’s XMPP functionality simply didn’t garner the adoption we were hoping for. It was never used at scale, and was mainly relegated to chat bots that needed compatibility with Google Talk. However, as Google phased out XMPP federation, such usefulness dwindled.
-
The Edge is Nothing Without the Fog
Edge computing is hot right now. The growing maturity of IoT networks ranging from industrial to VR applications means that there’s an enormous amount of discussion around moving from the cloud to the edge (from us as well). But edge computing is only the first step.
-
WebSockets with AWS Lambda
Dec 15, 2017 • posted by justin
• filed under api, faas, fanout, grip, scalability, websocketsFanout Cloud handles long-lived connections, such as HTTP streaming and WebSocket connections, on behalf of API backends. For projects that need to push data at scale, this can be a smart architecture. It also happens to be handy with function-as-a-service backends, such as AWS Lambda, which are not designed to handle long-lived connections on their own. By combining Fanout Cloud and Lambda, you can build serverless realtime applications.
Of course, Lambda can integrate with services such as AWS IoT to achieve a similar effect. The difference with Fanout Cloud is that it works at a lower level, giving you access to raw protocol elements. For example, Fanout Cloud enables you to build a Lambda-powered API that supports plain WebSockets, which is not possible with any other service.
To make integration easy, we’ve introduced FaaS libraries for Node.js and Python. Read on to learn how it all works.
-
High scalability with Fanout and Fastly
Nov 15, 2017 • posted by justin
• filed under api, fanout, grip, realtime, scalabilityFanout Cloud is for high scale data push. Fastly is for high scale data pull. Many realtime applications need to work with data that is both pushed and pulled, and thus can benefit from using both of these systems in the same application. Fanout and Fastly can even be connected together!
Using Fanout and Fastly in the same application, independently, is pretty straightforward. For example, at initialization time, past content could be retrieved from Fastly, and Fanout Cloud could provide future pushed updates. What does it mean to connect the two systems together though? Read on to find out.
-
Examining Mature APIs (Slack, Stripe, Box)
In our previous blog post, we discussed the disconnect between API pricing plans where you pay monthly for a set number of calls and regular developer use cases. We think competition will drive new pricing models that are more developer friendly – and a potential approach could be charging for calls based on their business value. Examining webhook events available via API from Stripe, Slack, and Box gives us a forward look into how this could work.
-
Dev-centric API pricing is the future
As folks who power realtime APIs, we’re always interested in broader trends in what is referred to as the “API Economy.” In the last couple of years, we (and everyone else) have seen the proliferation of APIs skyrocket. ProgrammableWeb indexes over 18,412 APIs. Even Walgreens has an API.
This has generally been a good thing for developers who want to build new technology. Instead of having to build your app from scratch, you can assemble distributed processes for everything from payments to messaging that are built and scaled by specialists, leaving you with more time to focus on your unique functionality. There are APIs and “as-a-services” (we’re one of them), for almost everything you can imagine – and this means developers are implementing more APIs in a single project than ever before.
-
Reliable Server-Sent Events for Django
Aug 3, 2017 • posted by justin
• filed under api, fanout, grip, pushpin, python, realtimeToday we’re pleased to introduce Django EventStream, a module that provides Server-Sent Events capability to your Django server application. It relies on Pushpin or Fanout Cloud to manage the client connections. Events can optionally be persisted to your database, for highly reliable delivery.
-
Pushpin reliable streaming
Jan 22, 2017 • posted by justin
• filed under api, grip, pushpinEarlier this month we discussed the challenges of pushing data reliably. Fanout products such as Pushpin (and Fanout Cloud, which runs Pushpin) do not entirely insulate developers from these challenges, as it is not possible to do so within our scope. However, we recently devised a way to reduce the pain involved.
Realtime APIs usually require receivers to juggle two data sources if they want to receive data reliably. For example, a client might listen for updates using a best-effort streaming API, and recover data using a REST API. So we thought, what if Pushpin could manage these two data sources, such that the client only needs to worry about one?
-
Push and reliability
In push architectures, one of the main challenges is delivering data reliably to receivers. There are many reasons for this:
- Most push architectures (including those developed by our company) use the publish-subscribe messaging pattern, which is unreliable.
- TCP’s built-in reliability is not enough to ensure delivery, as modern network sessions span multiple connections.
- Receivers can’t tell the difference between data loss and intentional silence.
- There is no one size fits all answer.
The last point trips up developers new to this problem space, who may wish for push systems to provide “guaranteed delivery.” If only it were that simple. Like many challenges in computer science, there isn’t a best answer, just trade-offs you are willing to accept.
Below we’ll go over the various issues and recommended practices around reliable push.
-
Moving from polling to long-polling
Nov 21, 2016 • posted by justin
• filed under api, api-design, grip, pushpinIf you’ve built a REST API that clients poll for updates, you’ve probably considered adding a realtime push mechanism. Maybe you’ve been putting it off due to the added complexity, or the impact it might have on your API contract. These are valid concerns, but push doesn’t have to be that complicated.
In this article we’ll discuss how to update an API to use long-polling. It assumes:
- You have an existing REST API.
- You have clients repeatedly polling this API.
Long-polling is not the same as “plain” polling. With long-polling, the server delays the response to the client if there is no new data yet. This enables the server to respond instantly whenever the data does change. Aside from providing actual realtime updates, what’s great about long-polling is that technically it’s still RESTful, requiring hardly any changes to your API contract or client code.
Of course, long-polling may not be as efficient as streaming mechanisms like Server-Sent Events or WebSockets, but it’s inarguably more efficient than plain-polling. Let’s compare:
Mechanism Latency Load Plain-polling As high as the polling interval (e.g. 5 second interval means updates will be up to 5 seconds late) High Long-polling Zero Order of magnitude reduction Long-polling is a great way to dip your feet in the realtime waters without having to dramatically change your API contract and client code.
-
Pushpin and RethinkDB meetup video
Oct 21, 2015 • posted by justin
• filed under api, pushpin, pythonA few months ago I presented at the RethinkDB meetup on the topic of building realtime APIs. Fortunately the talk was recorded and the video is below. Enjoy!
-
Runscope JWT authentication
Monday evening we had a particularly nasty outage: JWT authentication was broken, preventing anyone from using our HTTP API to publish data. The reason we didn’t catch this early on is because our manual test scripts turned out to be broken (reporting auth success when auth had failed.. yeesh!), and there was no authentication coverage in our external monitoring to fall back on.
In a perfect world, our external monitoring would test authentication. I’m happy to report that we are now doing this with Runscope! Getting this to work right was a little tricky since we use JWT, but it was made possible thanks to Runscope’s scripting feature.
-
Realtime API management with Pushpin and Kong
Jul 14, 2015 • posted by justin
• filed under api, grip, pushpin, websocketsPushpin is the open source reverse proxy for the realtime web. One of the benefits of Pushpin functioning as a proxy is that it can be combined with an API management system, such as Mashape’s Kong. Kong is the open source management layer for APIs. To use Kong with Pushpin, simply chain the two together on the same network path.
Why would you want to use an API management system with Pushpin? Realtime web services have many of the same concerns as request/response web services, and it can be helpful to centrally manage those aspects.
-
Building a realtime API with RethinkDB
May 20, 2015 • posted by justin
• filed under api, fanout, pushpin, pythonRethinkDB is a modern NoSQL database that makes it easy to build realtime web services. One of its standout features is called Changefeeds. Applications can query tables for ongoing changes, and RethinkDB will push any changes to applications as they happen. The Changefeeds feature is interesting for many reasons:
- You don’t need a separate message queue to wake up workers that operate on new data.
- Database writes made from anywhere will propagate out as changes. Use the RethinkDB dashboard to muck with data? Run a migration script? Listeners will hear about it.
- Filtering/squashing of change events within RethinkDB. In many cases it may be easier to filter events using ReQL than using a message queue and filtering workers.
This makes RethinkDB a compelling part of a realtime web service stack. In this article, we’ll describe how to use RethinkDB to implement a leaderboard API with realtime updates. Emphasis on API. Unlike other leaderboard examples you may have seen elsewhere, the focus here will be to create a clean API definition and use RethinkDB as part of the implementation. If you’re not sure what it means for an API to have realtime capabilities, check out this guide.
We’ll use the following components to build the leaderboard API:
- Database: RethinkDB, hosted on a Rackspace server.
- Web service: Django, hosted by Heroku.
- Realtime push to clients: Pushpin, hosted by Fanout Cloud.
Since the server app targets Heroku, we’ll be using environment variables for configuration and foreman for local testing.
Read on to see how it’s done. You can also look at the source.
-
Realtime API design guide
Apr 2, 2015 • posted by justin
• filed under api, api-design, webhooks, websocketsNew to the subject of realtime APIs? This article is the place to start! We’ll discuss the most common design approaches and their pros/cons, as well as link to the documentation of 16 public realtime APIs that you can use for inspiration.
-
Building a realtime API in Django
Nov 6, 2014 • posted by justin
• filed under api, grip, python, websocketsDjango is an awesome framework for building web services using the Python language. However, it is not well-suited for handling long-lived connections, which are needed for realtime data push. In this article we’ll explain how to pair Django with Fanout Cloud to reach realtime nirvana.
-
Pushing to 100,000 API clients simultaneously
Oct 30, 2013 • posted by justin
• filed under api, pushpin, scalabilityEarlier this year we announced the open source Pushpin project, a server component that makes it easy to scale out realtime HTTP and WebSocket APIs. Just what kind of scale are we talking about though? To demonstrate, we put together some code that pushes a truckload of data through a cluster of Pushpin instances. Here’s the output of its dashboard after a successful run:

Before getting into the details of how we did this, let’s first establish some goals:
- We want to scale an arbitrary realtime API. This API, from the perspective of a connecting client, shouldn’t need to be in any way specific to the components we are using to scale it.
- Ideally, we want to scale out the number of delivery servers but not the number of application servers. That is, we should be able to massively amplify the output of a modest realtime source.
- We want to push to all recipients simultaneously and we want the deliveries to complete in about 1 second. We’ll shoot for 100,000 recipients.
To be clear, sending data to 100K clients in the same instant is a huge level of traffic. Disqus recently posted that they serve 45K requests per second. If, using some very rough math, we say that a realtime push is about as heavy as half of a request, then our demonstration requires the same bandwidth as the entire Disqus network, if only for one second. This is in contrast to benchmarks that measure “connected” clients, such as the Tigase XMPP server’s 500K single-machine benchmark, where the clients participate conservatively over an extended period of time. Benchmarks like these are impressive in their own right, just be aware that they are a different kind of demonstration.
-
An HTTP reverse proxy for realtime
Apr 9, 2013 • posted by justin
• filed under api, grip, pushpinPushpin makes it easy to create HTTP long-polling, HTTP streaming, and WebSocket services using any web stack as the backend. It’s compatible with any framework, whether Django, Rails, ASP, PHP, Node, etc. Pushpin works as a reverse proxy, sitting in front of your server application and managing all of the open client connections.
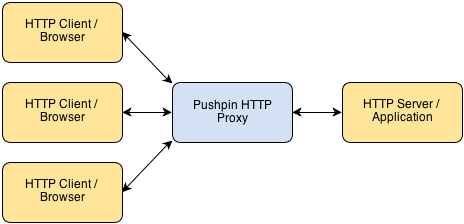
Communication between Pushpin and the backend server is done using conventional short-lived HTTP requests and responses. There is also a ZeroMQ interface for advanced users.
The approach is powerful for several reasons:
- The application logic can be written in the most natural way, using existing web frameworks.
- Scaling is easy and also natural. If your bottleneck is the number of recipients you can push realtime updates to, then add more Pushpin instances.
- It’s highly versatile. You define the HTTP/WebSocket exchanges between the client and server. This makes it ideal for building APIs.
-
Pollymer: a general-purpose long-polling library
Mar 19, 2013 • posted by justin
• filed under apiPollymer (not to be confused with Polymer, which it predates) is a general-purpose AJAX library designed for long-polling any protocol. Before you set off to write manual long-polling code again, consider using Pollymer for the task. Features include:
- Automatic retrying of failed requests, with an exponentially increasing delay between retries.
- Automatic re-polling on success, separated by a small randomized delay. Pass a function for the URL to be able to dynamically adjust the polling target.
- Workarounds for browser “busy” indications.
- JSON-P fallback for cross-domain requests on older browsers (requires server support).
-
Long-polling doesn’t totally suck
With all the interest in WebSockets lately, it would be easy to write off HTTP long-polling as a less capable, legacy mechanism. The truth is that long-polling is completely sufficient for today’s modern web applications, and additionally it enjoys many benefits not found in WebSockets or other mechanisms. Here’s why you might want to implement HTTP long-polling on purpose in the present day:
-
HTTP GRIP and the Proxy-and-Hold technique
Feb 10, 2013 • posted by justin
• filed under api, fanout, grip, protocolsUPDATE: The official GRIP specification now lives here and is more up to date.
Fanout’s ability to power any realtime HTTP API is based on what I call the proxy-and-hold technique. With this technique, an edge server handling HTTP or WebSocket connections for realtime purposes need not be concerned with the inner workings of the web application that it fronts. This keeps edge nodes dumb and generalized, allowing for straightforward scaling and also the possibility of sharing the nodes across multiple applications and services. To help explain how the technique works and why I believe it is an ideal way to develop any realtime HTTP application, I’ll walk us through my original thought process:
-
Using the API via XMPP
Jan 12, 2013 • posted by justin
• filed under api, fanout, protocols, xmppAs you may know, Fanout Cloud supports delivering data to both HTTP and XMPP clients/endpoints. What you may not know is that the Fanout Cloud API itself is accessible via both protocols, too. This means that not only can you publish messages or make configuration changes via REST, you can perform these same tasks by sending XMPP stanzas. Why would you want to do this? Well, in certain cases, XMPP may be a more convenient or more optimal way of accessing the Fanout Cloud API. Additionally, the fact that you can use the API via one protocol but publish data to an endpoint of the opposite protocol allows for crossover possibilities. For example, you can use the REST API to fire off XMPP stanzas, or use XMPP ad-hoc commands to stream data to HTTP clients.
-
Realtime multicasting over HTTP/XMPP
Sep 3, 2012 • posted by justin
• filed under api, fanout, protocols, xmppPush is hard. Often, implementing realtime push in a website or web service means having to use unfamiliar software or frameworks. If it isn’t an XMPP server with BOSH, then it’s an esoteric HTTP server framework like Node.js or Tornado. Further, while the knowledge and tools necessary for load balancing a traditional web service are commonly found these days, scaling out and operating a push architecture is less straightforward. The interactions between server nodes are different. The traffic patterns are different. Even if you’ve got a handle on whatever particular approach for push you’re using today, do you know how you’ll scale it tomorrow?
 • filed under
• filed under