subscribe via RSS
-
We've been acquired by Fastly
Mar 30, 2022 • posted by justin
 • filed under faas, fanout, grip, pushpin, realtime, scalability, websockets
• filed under faas, fanout, grip, pushpin, realtime, scalability, websocketsI’m excited to share that Fanout is now part of Fastly! Over the coming months we’ll be rolling out our realtime/push capabilities onto their global network.
See also Fastly’s announcement.
-
A cloud-native platform for push APIs
Apr 27, 2021 • posted by justin
• filed under api, grip, pushpin, realtime, scalability, websocketsToday we are excited to announce Fanout Platform!
Fanout Platform is infrastructure software for building HTTP streaming and WebSocket APIs. It is comprised of our open source project, Pushpin, along with special add-ons for scaling. Helm charts are available for installation on Kubernetes.
Here’s a short video that shows how easy it is to upgrade from Pushpin to Fanout Platform:
Read on to learn about why we are doing this, and how it works.
-
Vercel and WebSockets
Sep 21, 2020 • posted by justin
• filed under api, faas, grip, realtime, websocketsVercel makes it easy to deploy and scale HTTP APIs using Serverless Functions. However, it’s not possible to use serverless functions to host WebSocket APIs. Does this mean you need to give up on your hopes and dreams and set up normal servers to handle your WebSockets? No way! Vercel can be combined with Fanout Cloud to handle WebSocket connections without having to literally host them.

By using Vercel and Fanout Cloud together, API logic can be kept in one place. Fanout Cloud can manage the WebSocket connections, and invoke functions whenever there is client activity. What’s great about this approach is there’s nothing extra to deploy, and it works at high scale too.
-
Long-lived connections in a serverless world
Feb 15, 2019 • posted by justin
• filed under api, faas, fanout, grip, protocols, realtime, websocketsIn serverless architectures, application logic is often powered by short-lived execution environments. But what does this mean for long-lived connections? After all, many applications today depend on persistent WebSocket or SSE connections in order to exchange data in realtime.
The answer is unsurprising: either the execution limitations must be tolerated, or long-lived connections must be handled by a separate component. We’ll go over these approaches below.
-
WebSockets with AWS Lambda
Dec 15, 2017 • posted by justin
• filed under api, faas, fanout, grip, scalability, websocketsFanout Cloud handles long-lived connections, such as HTTP streaming and WebSocket connections, on behalf of API backends. For projects that need to push data at scale, this can be a smart architecture. It also happens to be handy with function-as-a-service backends, such as AWS Lambda, which are not designed to handle long-lived connections on their own. By combining Fanout Cloud and Lambda, you can build serverless realtime applications.
Of course, Lambda can integrate with services such as AWS IoT to achieve a similar effect. The difference with Fanout Cloud is that it works at a lower level, giving you access to raw protocol elements. For example, Fanout Cloud enables you to build a Lambda-powered API that supports plain WebSockets, which is not possible with any other service.
To make integration easy, we’ve introduced FaaS libraries for Node.js and Python. Read on to learn how it all works.
-
High scalability with Fanout and Fastly
Nov 15, 2017 • posted by justin
• filed under api, fanout, grip, realtime, scalabilityFanout Cloud is for high scale data push. Fastly is for high scale data pull. Many realtime applications need to work with data that is both pushed and pulled, and thus can benefit from using both of these systems in the same application. Fanout and Fastly can even be connected together!
Using Fanout and Fastly in the same application, independently, is pretty straightforward. For example, at initialization time, past content could be retrieved from Fastly, and Fanout Cloud could provide future pushed updates. What does it mean to connect the two systems together though? Read on to find out.
-
Reliable Server-Sent Events for Django
Aug 3, 2017 • posted by justin
• filed under api, fanout, grip, pushpin, python, realtimeToday we’re pleased to introduce Django EventStream, a module that provides Server-Sent Events capability to your Django server application. It relies on Pushpin or Fanout Cloud to manage the client connections. Events can optionally be persisted to your database, for highly reliable delivery.
-
Pushpin reliable streaming
Jan 22, 2017 • posted by justin
• filed under api, grip, pushpinEarlier this month we discussed the challenges of pushing data reliably. Fanout products such as Pushpin (and Fanout Cloud, which runs Pushpin) do not entirely insulate developers from these challenges, as it is not possible to do so within our scope. However, we recently devised a way to reduce the pain involved.
Realtime APIs usually require receivers to juggle two data sources if they want to receive data reliably. For example, a client might listen for updates using a best-effort streaming API, and recover data using a REST API. So we thought, what if Pushpin could manage these two data sources, such that the client only needs to worry about one?
-
Moving from polling to long-polling
Nov 21, 2016 • posted by justin
• filed under api, api-design, grip, pushpinIf you’ve built a REST API that clients poll for updates, you’ve probably considered adding a realtime push mechanism. Maybe you’ve been putting it off due to the added complexity, or the impact it might have on your API contract. These are valid concerns, but push doesn’t have to be that complicated.
In this article we’ll discuss how to update an API to use long-polling. It assumes:
- You have an existing REST API.
- You have clients repeatedly polling this API.
Long-polling is not the same as “plain” polling. With long-polling, the server delays the response to the client if there is no new data yet. This enables the server to respond instantly whenever the data does change. Aside from providing actual realtime updates, what’s great about long-polling is that technically it’s still RESTful, requiring hardly any changes to your API contract or client code.
Of course, long-polling may not be as efficient as streaming mechanisms like Server-Sent Events or WebSockets, but it’s inarguably more efficient than plain-polling. Let’s compare:
Mechanism Latency Load Plain-polling As high as the polling interval (e.g. 5 second interval means updates will be up to 5 seconds late) High Long-polling Zero Order of magnitude reduction Long-polling is a great way to dip your feet in the realtime waters without having to dramatically change your API contract and client code.
-
Serverless WebSockets
Sep 29, 2016 • posted by justin
• filed under grip, pushpin, websocketsServerless development is a hot topic lately. Development & operations of a web service can be greatly simplified by writing your application logic as short-lived functions, and relying on outside organizations for the development of all the other components in your stack (e.g. databases, gateways, container engines, etc). The term “serverless” is a bit funny because of course there are still servers in your stack, and they may even be your own servers, but the main idea is you no longer have to worry about your own long-running application code.
This all sounds great, but an issue arises: in this serverless world, how do you support long-lived connections (e.g. HTTP streaming/WebSocket connections) for realtime data push, without long-running application code? By delegating connection management to another component, of course! In this article we’ll talk about how to build a simple WebSocket service with Pushpin, using Microcule for running the backend worker function.
-
Streaming historical data
One of the most useful features of Pushpin is the ability to combine a request for historical data with a request to listen for updates. For example, an HTTP streaming request can respond immediately with some initial data before converting into a pubsub subscription. As of version 1.12.0, this ability is made even more powerful:
- Stream hold responses (
Grip-Hold: stream) from the origin server can now have a response body of unlimited size. This works by streaming the body from the origin server to the client before processing the GRIP instruction headers. Note that this only works forstreamholds. Forresponseholds, the response body is still limited to 100,000 bytes. - Responses from the origin server may contain a
nextlink using theGrip-Linkheader, to tell Pushpin to make a request to a specified URL after the current request to the origin finishes, and to leave the request with the client open while doing this. The response body of any such subsequent request is appended to the ongoing response to the client. This enables the server to reply with a large response to the client by serving a bunch of smaller chunks to Pushpin, and it also allows the server to defer the preparation of GRIP hold instructions until a later request in the session.
- Stream hold responses (
-
Realtime API management with Pushpin and Kong
Jul 14, 2015 • posted by justin
• filed under api, grip, pushpin, websocketsPushpin is the open source reverse proxy for the realtime web. One of the benefits of Pushpin functioning as a proxy is that it can be combined with an API management system, such as Mashape’s Kong. Kong is the open source management layer for APIs. To use Kong with Pushpin, simply chain the two together on the same network path.
Why would you want to use an API management system with Pushpin? Realtime web services have many of the same concerns as request/response web services, and it can be helpful to centrally manage those aspects.
-
Stateless WebSockets with Express and Pushpin
Mar 9, 2015 • posted by justin
• filed under grip, pushpin, websocketsOne of the most interesting features of the Pushpin proxy is its ability to gateway between WebSocket clients and plain HTTP backend servers. In this article, we’ll demonstrate how to build a WebSocket service using Express as the HTTP backend behind Pushpin.
-
Building a realtime API in Django
Nov 6, 2014 • posted by justin
• filed under api, grip, python, websocketsDjango is an awesome framework for building web services using the Python language. However, it is not well-suited for handling long-lived connections, which are needed for realtime data push. In this article we’ll explain how to pair Django with Fanout Cloud to reach realtime nirvana.
-
An HTTP reverse proxy for realtime
Apr 9, 2013 • posted by justin
• filed under api, grip, pushpinPushpin makes it easy to create HTTP long-polling, HTTP streaming, and WebSocket services using any web stack as the backend. It’s compatible with any framework, whether Django, Rails, ASP, PHP, Node, etc. Pushpin works as a reverse proxy, sitting in front of your server application and managing all of the open client connections.
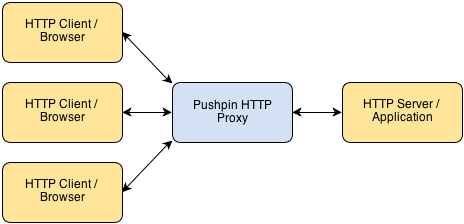
Communication between Pushpin and the backend server is done using conventional short-lived HTTP requests and responses. There is also a ZeroMQ interface for advanced users.
The approach is powerful for several reasons:
- The application logic can be written in the most natural way, using existing web frameworks.
- Scaling is easy and also natural. If your bottleneck is the number of recipients you can push realtime updates to, then add more Pushpin instances.
- It’s highly versatile. You define the HTTP/WebSocket exchanges between the client and server. This makes it ideal for building APIs.
-
HTTP GRIP and the Proxy-and-Hold technique
Feb 10, 2013 • posted by justin
• filed under api, fanout, grip, protocolsUPDATE: The official GRIP specification now lives here and is more up to date.
Fanout’s ability to power any realtime HTTP API is based on what I call the proxy-and-hold technique. With this technique, an edge server handling HTTP or WebSocket connections for realtime purposes need not be concerned with the inner workings of the web application that it fronts. This keeps edge nodes dumb and generalized, allowing for straightforward scaling and also the possibility of sharing the nodes across multiple applications and services. To help explain how the technique works and why I believe it is an ideal way to develop any realtime HTTP application, I’ll walk us through my original thought process: