Streaming historical data
 • filed under
• filed under One of the most useful features of Pushpin is the ability to combine a request for historical data with a request to listen for updates. For example, an HTTP streaming request can respond immediately with some initial data before converting into a pubsub subscription. As of version 1.12.0, this ability is made even more powerful:
- Stream hold responses (
Grip-Hold: stream) from the origin server can now have a response body of unlimited size. This works by streaming the body from the origin server to the client before processing the GRIP instruction headers. Note that this only works forstreamholds. Forresponseholds, the response body is still limited to 100,000 bytes. - Responses from the origin server may contain a
nextlink using theGrip-Linkheader, to tell Pushpin to make a request to a specified URL after the current request to the origin finishes, and to leave the request with the client open while doing this. The response body of any such subsequent request is appended to the ongoing response to the client. This enables the server to reply with a large response to the client by serving a bunch of smaller chunks to Pushpin, and it also allows the server to defer the preparation of GRIP hold instructions until a later request in the session.
How “Next” links work
For example, suppose an origin server has resources /first and /second, with responses from the first using a GRIP next link to point to the second.
Example request to /first:
GET /first HTTP/1.1
Host: example.comOrigin server response:
HTTP/1.1 200 OK
Content-Type: text/plain
Grip-Link: </second>; rel=next
helloExample request to /second:
GET /second HTTP/1.1
Host: example.comOrigin server response:
HTTP/1.1 200 OK
Content-Type: text/plain
worldIf a client makes a request to /first through Pushpin, it will receive a response containing the headers of the first resource and the combined body of both resources:
HTTP/1.1 200 OK
Content-Type: text/plain
hello
worldPushpin follows the GRIP next link without the client being aware that it is happening. Here’s a sequence diagram of the process:
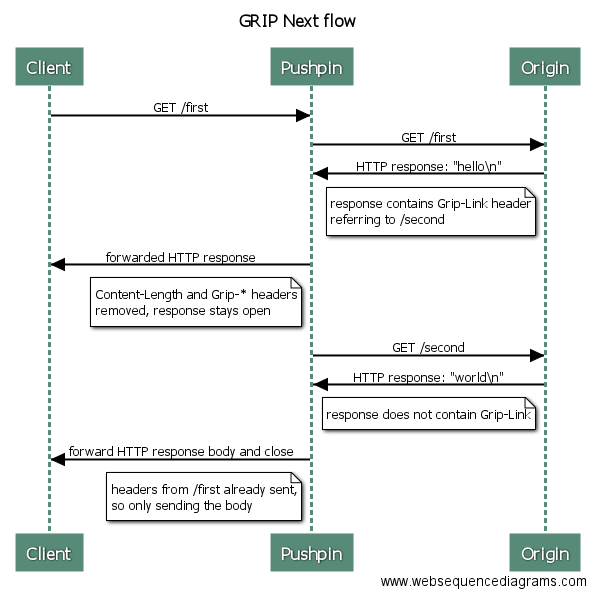
It is possible for the response of a followed link to contain another link, and so an unlimited number of requests can be chained together to return a large response to the client. This is safe to do because Pushpin only requests subsequent data as fast as the client can receive it (backpressure effect), and so the rate at which Pushpin makes requests to the origin server shouldn’t be much faster than the rate at which the client could have made the requests on its own.
Streaming large history
The main use-case of next links is to stream large amounts of historical content. For example, let’s say you want to build a Server-Sent Events (SSE) endpoint that initially returns all events after the last known event specified by the client. The client could make a request like this:
GET /stream HTTP/1.1
Host: example.com
Last-Event-ID: 1000Let’s also say that the server has sent 10,000 events so far, meaning that the client is 9,000 events behind. In a Pushpin architecture, the origin server could handle this in two ways:
- Respond with all 9000 events in a single response containing
Grip-Hold: streamheader. If the individual events are big enough to cause the overall response to be quite large, then this should only be done by origin servers capable of streaming the response without tying up a thread. - Respond with smaller batches of events, say 100 at a time across 90 requests, with each response pointing to the next “page” of events using a GRIP
nextlink. The final response would contain aGrip-Hold: streamheader. With this approach, there is no issue with large responses tying up threads on the origin server.
The client would then see:
HTTP/1.1 200 OK
Content-Type: text/event-stream
id: 1001
data: { ... data of event 1001 ... }
id: 1002
data: { ... data of event 1002 ... }
id: 1003
data: { ... data of event 1003 ... }
[...]
id: 10000
data: { ... data of event 10000 ... }After receiving the 10,000th event, the client would be caught up and the response would pause until new events need to be sent.
If GRIP next links are used, the URLs could be something like /stream?last-id={n}, where {n} is the ID of the last event provided in each response from the origin server:
HTTP/1.1 200 OK
Content-Type: text/event-stream
Grip-Link: </stream?last-id=1100>; rel=next
id: 1001
data: { ... data of event 1001 ... }
id: 1002
data: { ... data of event 1002 ... }
id: 1003
data: { ... data of event 1003 ... }
[...]
id: 1100
data: { ... data of event 1100 ... }This way the origin server can operate statelessly, serving a maximum number of events at a time. Pushpin will automatically page through all of the events.
Choosing a format for large responses
If your REST API already has concepts such as collections and paging, you might wonder about using your existing paging URLs as GRIP next links. However, in most cases this won’t work the way you’d expect and so you’ll want to use different URLs that produce an alternate response format intended for streaming. For example, if your collection APIs return responses as JSON arrays, then when Pushpin concatenates everything together the client might see a response that looks like this:
HTTP/1.1 200 OK
Content-Type: application/json
[
{"value": "1"}
{"value": "2"}
{"value": "3"}
]
[
{"value": "4"}
{"value": "5"}
{"value": "6"}
]
[
{"value": "7"}
{"value": "8"}
{"value": "9"}
]This would certainly be an unusual style of response. Clients wouldn’t have an easy way to parse out each array. It’s also not valid JSON, although that alone isn’t a major problem for streaming data.
It may be tempting to want to try to create a valid JSON array by being clever with your paging URLs (e.g. by having the first response prefixed with a [ character, middle responses without array framing, and the final response ending with a ], but if the response is large then this would require the client to use a streaming JSON parser which again would be unusual. Also, if the request then converts into a stream hold, the first pushed event would break your beautiful valid JSON anyway. Of course you could avoid that by not closing the array with ] in the initial data, but still you’re back to needing a streaming JSON parser.
Instead, large response data should be formatted in a way that is easy for clients to parse as a stream. We recommend using lines of text, where each line is an individual piece of data (like Twitter’s streaming API) or a collection of lines is an individual piece of data (SSE). This way the outer framing is very easy to parse, and each piece of inner data can use a more complex format (e.g. JSON).
For example, a response containing JSON blobs separated by newlines should be easy for clients to parse:
HTTP/1.1 200 OK
Content-Type: text/plain
{"value": "1"}
{"value": "2"}
{"value": "3"}
{"value": "4"}
{"value": "5"}
{"value": "6"}
{"value": "7"}
{"value": "8"}
{"value": "9"}It’s just bytes
When Pushpin is servicing a request for historical data, it is simply relaying bytes from the origin server. The data doesn’t have to be an exact replay of what was originally generated. For example, if your server pushes events about an object being added and removed over and over again, currently subscribed clients might receive all of these change events, but a newly arriving client requesting historical state might only need to receive the most recent result of these changes. The origin server can decide what response is best based on the query provided by the client, consolidating data as necessary. To Pushpin, it’s all just bytes.
A better developer experience for your API
Being able to receive a potentially limitless amount of historical data when setting up a streaming connection makes for a clean API.
Strictly speaking, having a server that can send a ton of data in a single response is not the only way to send a ton of data to the client. Clients should know how to page forward through historical data on their own, if at the very least in order to recover from disconnections. For example, with SSE format your server could return 100 historical events at a time and close the connection after each batch is sent. The client would reconnect and supply a Last-Event-ID header based on the last event received, and eventually the client would catch up and the server can push future data after that. However this is a pretty awkward developer experience for a streaming API.
Sending all the historical data down a single response stream would result in a much cleaner experience. Plus you’ll optimize network usage at the last mile. We hope Pushpin can make it easier for API providers to stream historical data in this way.
Recent posts
-
We've been acquired by Fastly
-
A cloud-native platform for push APIs
-
Vercel and WebSockets
-
Rewriting Pushpin's connection manager in Rust
-
Let's Encrypt for custom domains