HTTP GRIP and the Proxy-and-Hold technique
Feb 10, 2013 • posted by justin  • filed under api, fanout, grip, protocols
• filed under api, fanout, grip, protocols
UPDATE: The official GRIP specification now lives here and is more up to date.
Fanout’s ability to power any realtime HTTP API is based on what I call the proxy-and-hold technique. With this technique, an edge server handling HTTP or WebSocket connections for realtime purposes need not be concerned with the inner workings of the web application that it fronts. This keeps edge nodes dumb and generalized, allowing for straightforward scaling and also the possibility of sharing the nodes across multiple applications and services. To help explain how the technique works and why I believe it is an ideal way to develop any realtime HTTP application, I’ll walk us through my original thought process:
Scaling push requires delegation
As with pretty much any scaling challenge, the key to publishing messages to large sets of subscribers is to divide the work among many machines. Additionally, it can be beneficial to delegate work to different networks. The bursty nature of push can cause you to saturate your network connection, and this can be mitigated by passing off work to machines that are intentionally physically remote and that would use different network paths to reach subscribers.
Push should have independent state
If we’re going to have a cluster of delivery nodes, potentially geographically distributed or tiered, it would be ideal to treat push as a one-way delivery mechanism that is not necessarily synchronized with the rest of the application. For example, if a client is able to receive the same kinds of information via two interfaces, one pull (to query for existing data) and one push (to receive updates), then it is conceivable that the client may sometimes receive the same information on both interfaces (imagine the client querying for data the moment a realtime update is sent). In this case it is the client’s job to sort things out.
As it happens, this is how publish-subscribe systems tend to be built anyway.
Delivery nodes should outnumber application nodes
When scaling traditional web traffic with a CDN such as Amazon CloudFront or CloudFlare, the number of nodes in the CDN service will almost certainly exceed the number of nodes of your application. After all, if your application has more web server nodes than your CDN has nodes then you wouldn’t really need a CDN now would you? In much the same way, it is sensible that the number of push delivery nodes should outnumber your application nodes.
Proxy the logic
If we will have more edge nodes than application nodes, good design would suggest (keeping the CDN model in mind) that the edge nodes be kept as generic as possible, leaving application-specific logic to your application nodes. I would venture a guess that most realtime API edge server code written today is very much tied to the application being developed, using special web server frameworks glued to specific storage and notification mechanisms. Such code is likely not reusable for different applications and it is almost certainly not reusable cross-vendor. I think we can do better than this, and move the application-specifics back one layer.
The following strategy is then proposed: when an HTTP request is received by the edge node, it should query an application node behind it for instruction. If the correct course of action is for the edge node to reply with an HTTP response immediately, then the application node would say so in response to the query by the edge node. If the edge should instead hold the connection open for reuse (i.e. long polling or streaming), then the application node would say so. Additionally, there should be an understood or negotiated way for the application to send data down a connection held open by the edge node in the future. This approach is what is meant by the term proxy-and-hold.
HTTP, duh
Rather than invent a new protocol that the edge uses to query a backend application node, let’s just reuse HTTP and make the edge behave like an HTTP proxy. When a request is received by the edge node, it will forward it as-is to a backend application node running a web server. If the application wants to reply with data immediately, it replies with a normal HTTP response, which the edge node then forwards as-is back to the client. If, instead, the application node wishes to have the edge hold a connection open for future use, it will reply with an HTTP response using a special MIME type to indicate channel binding instructions. The edge will bind the connection to one or more channel identifiers, and the application can send data down existing connections by providing the edge with payloads and channel targets. How the application pushes this data to the edge node need not necessarily be HTTP-based, although having an HTTP-based interface for this step would certainly be convenient.
One huge advantage of using HTTP for communication between the edge node and the web application here is that it provides the most natural means of development. For example, if you’re already using some other web server and framework for developing the rest of your API, there’s no need to use some completely separate server and framework just to implement the realtime endpoints. Additionally, you can make any arbitrary endpoint realtime capable. No need to split realtime and non-realtime endpoints on different subdomains, for example.
Generic Realtime Intermediary Protocol
In an attempt to standardize the interface between the edge node and the application node, I dub it “GRIP”, the Generic Realtime Intermediary Protocol.
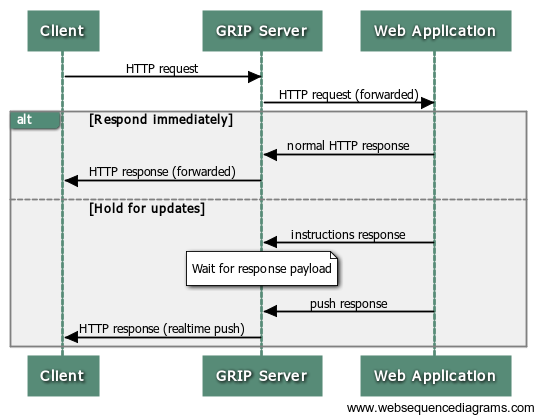
To control a GRIP service, the web application responds to requests by setting the response content type to application/grip-instruct and including JSON-formatted instructions in the body. For example:
HTTP/1.1 200 OK
Content-Type: application/grip-instruct
{
"hold": {
"mode": "response",
"channels": [
{
"name": "mychannel"
}
]
},
"response": {
"body": "{}\n"
}
}This would instruct the GRIP server to hold the HTTP connection open as a long-poll, listening for updates on the channel “mychannel”. If enough time passes, the GRIP server will timeout the request by responding to the client with an empty JSON dictionary (as described by the “body” field).
To push data on a channel, the web application would make a REST API call to a special endpoint operated by the GRIP server:
POST /publish/ HTTP/1.0
Content-Type: application/json
{
"items": [
{
"channel": "mychannel",
"formats": {
"http-response": {
"headers": {
"Content-Type": "application/json"
},
"body": "{\"foo\": \"bar\"}\n"
}
}
}
]
}Where this endpoint would live would be dependent on the GRIP server in use. Upon making the above POST request, the GRIP server would reply to the original held connection as such:
HTTP/1.1 200 OK
Content-Type: application/json
{ "foo": "bar" }There you have it! There is still no official draft document of the protocol, but this is something we will publish soon. Until then, I hope you find the GRIP concept compelling, and encourage you to implement the technique.
And, of course, be sure to check out Fanout Cloud, which is itself a GRIP service.
Recent posts
-
We've been acquired by Fastly
-
A cloud-native platform for push APIs
-
Vercel and WebSockets
-
Rewriting Pushpin's connection manager in Rust
-
Let's Encrypt for custom domains