Realtime processing and edge computing: the end of the cloud?
Sep 6, 2017 • posted by daniel  • filed under realtime
• filed under realtime
At Fanout we’re always interested in trends involving moving and processing data in realtime. A major shift is coming, driven by the rise of connected devices and the vast amount of data they are going to collect. According to a Gartner report, 8.4 billion connected “things” will be in use in 2017, representing a 31% increase from 2016 – and every one of these IoT devices is going to need to collect, process, and transmit data in order to be effective.
Moving from the cloud to the edge
Acting on data at the ‘edge’ (as this network of device endpoints is known) is a new frontier for our cloud-based world. The cloud may be a physically distributed group of servers, but it’s centralized from a network perspective – and centralized processing of data isn’t fast enough for IoT applications. Edge data needs to be acted on in realtime, whether to show relevant sensor-based advertising in a retail application or react to mission-critical alert information from a sensor on an oil rig.
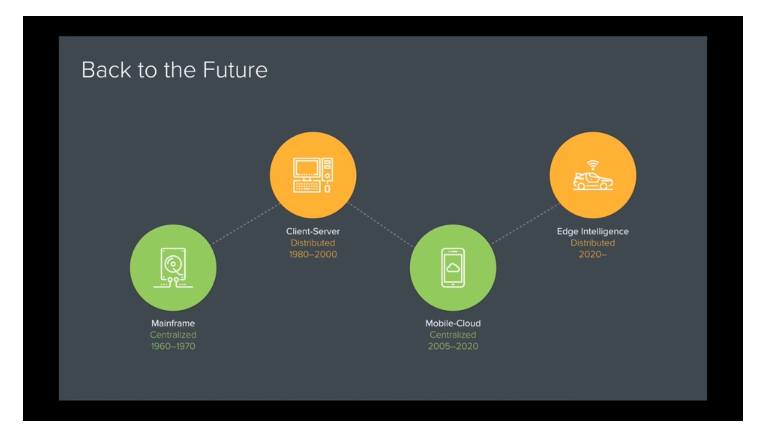
A16z’s Peter Levine has a great talk called The End of Cloud Computing that outlines these trends in more detail. In an interview with the WSJ, Peter summed up things nicely with an example: “A self-driving car is a data center on wheels. And it has 200-plus central processing units. It’s got to do all its computation at the endpoint and only pass back to the cloud, if it’s connected at all, important bits of curated information.”
Every network of devices is becoming it’s own datacenter – it’s just located at the edge of the network, instead of the center.
The edge doesn’t act alone
How to decide what information to curate and send back for processing? Sensors may need all available data to react to changes at the edge, but that doesn’t mean that they can or should transmit all of it back. Bandwidth, latency, and network availability are all factors – especially for IoT devices in regions or locations with poor connectivity.
Properly processing data to send back to the cloud in realtime is crucial for effective edge computing. Processing for edge data can include filtering (to include or exclude duplicate or redundant events) or aggregation (condensing time-sensitive data to reduce granularity). Efficient management of data at the edge allows pushing of the most actionable data back to the center of the network, where machine learning and big data algorithms can be applied to improve the reactions of edge endpoints. Improving the speed of this learning cycle means quicker improvements – and so moving data in realtime where possible is paramount.
Network architecture and “the fog”
We’ve briefly covered the switch from ‘the cloud’ to ‘the edge’ – but these terms are overly simplistic. There’s increasing overlap (sometimes referred to as ‘the fog’) between these two poles – and effective management of network architecture across the continuum will be crucial for companies gathering large amounts of data at the edge. Where to distribute computation, communication, control, and storage tasks from the edge to the cloud and how to best resource for them will be essential questions to answer moving forward.
Recent posts
-
We've been acquired by Fastly
-
A cloud-native platform for push APIs
-
Vercel and WebSockets
-
Rewriting Pushpin's connection manager in Rust
-
Let's Encrypt for custom domains