subscribe via RSS
categories: api, api-design, community, condure, faas, fanout, grip, mongrel2, protocols, pushpin, python, realtime, rust, scalability, security, usability, walkthroughs, webhooks, websockets, xmpp, zeromq, zurl
-
Hacker News Live Comments
Feb 16, 2014 • posted by justin
 • filed under fanout
• filed under fanoutEarlier this week, a bookmarklet was released that enlivens Hacker News comment threads. This thing makes me feel like I have magic powers. You have no idea how often I would refresh pages on HN before I started using this, especially on posts that are my own or that I had commented on. Now I can simply leave pages open in tabs and go about my day. The page titles update whenever there are new comments.
-
How to safely invoke Webhooks
Jan 27, 2014 • posted by justin
• filed under security, webhooksHTTP callbacks (aka Webhooks) are great for sending notifications to remote servers in realtime. In most setups, the URLs to contact are provided by foreign entities. All your application needs to do is allow such URLs to be registered, and then hit them whenever interesting things happen. Easy enough, right?
Not so fast. What if someone provides a URL such as
http://localhost:10000/destructive-command/and you’ve got an internal web service running on that port? Under normal circumstances, you might not expect this service to be accessible from the outside. Perhaps you have a firewall, or perhaps the internal service binds explicitly to the localhost interface. Either way, the HTTP callback pattern provides attackers an avenue to access this service from within your internal network, bypassing these kinds of expected security measures. -
Pushing to 100,000 API clients simultaneously
Oct 30, 2013 • posted by justin
• filed under api, pushpin, scalabilityEarlier this year we announced the open source Pushpin project, a server component that makes it easy to scale out realtime HTTP and WebSocket APIs. Just what kind of scale are we talking about though? To demonstrate, we put together some code that pushes a truckload of data through a cluster of Pushpin instances. Here’s the output of its dashboard after a successful run:

Before getting into the details of how we did this, let’s first establish some goals:
- We want to scale an arbitrary realtime API. This API, from the perspective of a connecting client, shouldn’t need to be in any way specific to the components we are using to scale it.
- Ideally, we want to scale out the number of delivery servers but not the number of application servers. That is, we should be able to massively amplify the output of a modest realtime source.
- We want to push to all recipients simultaneously and we want the deliveries to complete in about 1 second. We’ll shoot for 100,000 recipients.
To be clear, sending data to 100K clients in the same instant is a huge level of traffic. Disqus recently posted that they serve 45K requests per second. If, using some very rough math, we say that a realtime push is about as heavy as half of a request, then our demonstration requires the same bandwidth as the entire Disqus network, if only for one second. This is in contrast to benchmarks that measure “connected” clients, such as the Tigase XMPP server’s 500K single-machine benchmark, where the clients participate conservatively over an extended period of time. Benchmarks like these are impressive in their own right, just be aware that they are a different kind of demonstration.
-
Publishing JSON over XMPP
Oct 9, 2013 • posted by justin
• filed under fanout, protocols, xmppAt Fanout, we’ve developed a powerful publish-subscribe system for fronting custom APIs. Sometimes, though, API design is too much to think about and all you want to do is push some JSON.
To address this need, we initially created our own proprietary JSON-publishing protocol (a.k.a. “FPP”) and corresponding client library. This made it possible for developers to implement realtime updates in just a few lines of code, transported by magic. While this system worked well enough, it wasn’t terribly satisfying to have invented yet-another-protocol in order to accomplish this. Sure, every other pubsub cloud service has done the same thing, but the status quo makes for a bunch of redundant efforts that all achieve more-or-less the same result, and it hampers interoperability. So, lately, we’ve been looking into how we could adapt an existing standard for pushing JSON.
-
Lowering barriers
Sep 18, 2013 • posted by justin
• filed under fanout, usabilityYou know how it’s hard to notice your own typos? That’s how it felt to finally implement the latest round of usability fixes for Fanout Cloud. The service has always meant to be easy to use, and for the longest time I didn’t think we needed to change anything. Despite the fact that we’d sometimes receive feedback to the contrary, or that we’d sometimes observe confusion (judging by the number of incomplete accounts), I insisted that the service was as easy to use as it possibly could be. If there was any difficulty, it was of the necessary kind.
-
An HTTP reverse proxy for realtime
Apr 9, 2013 • posted by justin
• filed under api, grip, pushpinPushpin makes it easy to create HTTP long-polling, HTTP streaming, and WebSocket services using any web stack as the backend. It’s compatible with any framework, whether Django, Rails, ASP, PHP, Node, etc. Pushpin works as a reverse proxy, sitting in front of your server application and managing all of the open client connections.
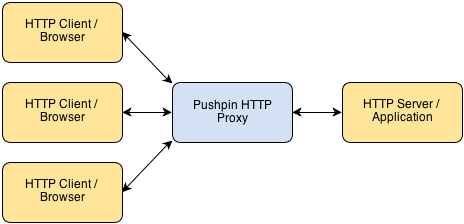
Communication between Pushpin and the backend server is done using conventional short-lived HTTP requests and responses. There is also a ZeroMQ interface for advanced users.
The approach is powerful for several reasons:
- The application logic can be written in the most natural way, using existing web frameworks.
- Scaling is easy and also natural. If your bottleneck is the number of recipients you can push realtime updates to, then add more Pushpin instances.
- It’s highly versatile. You define the HTTP/WebSocket exchanges between the client and server. This makes it ideal for building APIs.
-
Pollymer: a general-purpose long-polling library
Mar 19, 2013 • posted by justin
• filed under apiPollymer (not to be confused with Polymer, which it predates) is a general-purpose AJAX library designed for long-polling any protocol. Before you set off to write manual long-polling code again, consider using Pollymer for the task. Features include:
- Automatic retrying of failed requests, with an exponentially increasing delay between retries.
- Automatic re-polling on success, separated by a small randomized delay. Pass a function for the URL to be able to dynamically adjust the polling target.
- Workarounds for browser “busy” indications.
- JSON-P fallback for cross-domain requests on older browsers (requires server support).
-
Long-polling doesn’t totally suck
With all the interest in WebSockets lately, it would be easy to write off HTTP long-polling as a less capable, legacy mechanism. The truth is that long-polling is completely sufficient for today’s modern web applications, and additionally it enjoys many benefits not found in WebSockets or other mechanisms. Here’s why you might want to implement HTTP long-polling on purpose in the present day:
-
HTTP GRIP and the Proxy-and-Hold technique
Feb 10, 2013 • posted by justin
• filed under api, fanout, grip, protocolsUPDATE: The official GRIP specification now lives here and is more up to date.
Fanout’s ability to power any realtime HTTP API is based on what I call the proxy-and-hold technique. With this technique, an edge server handling HTTP or WebSocket connections for realtime purposes need not be concerned with the inner workings of the web application that it fronts. This keeps edge nodes dumb and generalized, allowing for straightforward scaling and also the possibility of sharing the nodes across multiple applications and services. To help explain how the technique works and why I believe it is an ideal way to develop any realtime HTTP application, I’ll walk us through my original thought process:
-
Using the API via XMPP
Jan 12, 2013 • posted by justin
• filed under api, fanout, protocols, xmppAs you may know, Fanout Cloud supports delivering data to both HTTP and XMPP clients/endpoints. What you may not know is that the Fanout Cloud API itself is accessible via both protocols, too. This means that not only can you publish messages or make configuration changes via REST, you can perform these same tasks by sending XMPP stanzas. Why would you want to do this? Well, in certain cases, XMPP may be a more convenient or more optimal way of accessing the Fanout Cloud API. Additionally, the fact that you can use the API via one protocol but publish data to an endpoint of the opposite protocol allows for crossover possibilities. For example, you can use the REST API to fire off XMPP stanzas, or use XMPP ad-hoc commands to stream data to HTTP clients.