subscribe via RSS
categories: api, api-design, community, condure, faas, fanout, grip, mongrel2, protocols, pushpin, python, realtime, rust, scalability, security, usability, walkthroughs, webhooks, websockets, xmpp, zeromq, zurl
-
Examining Mature APIs (Slack, Stripe, Box)
In our previous blog post, we discussed the disconnect between API pricing plans where you pay monthly for a set number of calls and regular developer use cases. We think competition will drive new pricing models that are more developer friendly – and a potential approach could be charging for calls based on their business value. Examining webhook events available via API from Stripe, Slack, and Box gives us a forward look into how this could work.
-
Dev-centric API pricing is the future
As folks who power realtime APIs, we’re always interested in broader trends in what is referred to as the “API Economy.” In the last couple of years, we (and everyone else) have seen the proliferation of APIs skyrocket. ProgrammableWeb indexes over 18,412 APIs. Even Walgreens has an API.
This has generally been a good thing for developers who want to build new technology. Instead of having to build your app from scratch, you can assemble distributed processes for everything from payments to messaging that are built and scaled by specialists, leaving you with more time to focus on your unique functionality. There are APIs and “as-a-services” (we’re one of them), for almost everything you can imagine – and this means developers are implementing more APIs in a single project than ever before.
-
Taking user experiences to the next level (with realtime)
Sep 22, 2017 • posted by daniel
 • filed under realtime
• filed under realtimeRealtime is increasingly becoming table stakes for messaging, collaboration, or event apps. But this doesn’t mean there isn’t room for improvement – and there are all sorts of engaging ways to add realtime to apps that don’t have it yet. We’ll dive into some examples and best practices.
-
Realtime processing and edge computing: the end of the cloud?
Sep 6, 2017 • posted by daniel
• filed under realtimeAt Fanout we’re always interested in trends involving moving and processing data in realtime. A major shift is coming, driven by the rise of connected devices and the vast amount of data they are going to collect. According to a Gartner report, 8.4 billion connected “things” will be in use in 2017, representing a 31% increase from 2016 – and every one of these IoT devices is going to need to collect, process, and transmit data in order to be effective.
-
Realtime data and continuous delivery
Aug 18, 2017 • posted by daniel
• filed under realtimeSoftware development teams are beginning to realize the benefits of continuous, test-driven delivery of new releases.
Instead of a single, milestone release (waterfall development) or multiple, internal test releases before major external ones (agile development), continuous delivery focuses on constant releasing of features to market throughout the development process.
The goal of continuous delivery is that code is always ready to deploy and features are constantly rolled out independent of ‘releases’ – and doing so properly requires realtime data.
-
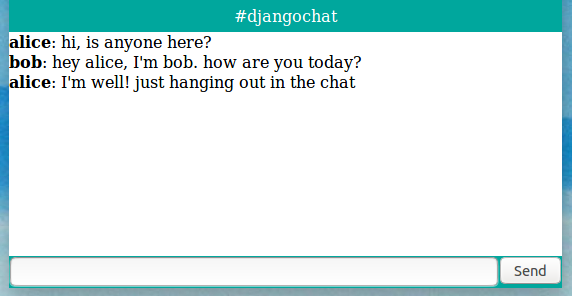
Building a realtime chat app with Django and Fanout Cloud
Aug 14, 2017 • posted by justin
 • filed under fanout, python, realtime
• filed under fanout, python, realtimeChat is one of the most popular uses of realtime data. In this article we’ll explain how to build a web chat app in Django, using Django EventStream and Fanout Cloud. The Django EventStream module makes it easy to push JSON events through Fanout Cloud to connected clients.
-
Reliable Server-Sent Events for Django
Aug 3, 2017 • posted by justin
• filed under api, fanout, grip, pushpin, python, realtimeToday we’re pleased to introduce Django EventStream, a module that provides Server-Sent Events capability to your Django server application. It relies on Pushpin or Fanout Cloud to manage the client connections. Events can optionally be persisted to your database, for highly reliable delivery.
-
Realtime data for smart notifications
Jul 29, 2017 • posted by daniel
• filed under realtime, walkthroughsIt’s becoming the new normal that messaging and collaboration apps and platforms are available across multiple devices.
Business tools like Slack and JIRA offer feature-rich mobile apps, and users increasingly consume content from social networks like Facebook on their mobile devices instead of a desktop or laptop.
This isn’t a surprise – and we’re here to share our perspective on how developers can use realtime data to provide cross-platform users with the best notification experience.
-
What is realtime?
Jun 30, 2017 • posted by daniel
• filed under realtime, walkthroughsMany software developers are familiar with realtime, but we believe that realtime concepts and user experiences are becoming increasingly important for less technical individuals to understand.
At Fanout, we power realtime APIs to instantly push data to endpoints – which can range from the actual endpoints of an API (the technical term) to external businesses or end users. We use the word in this post loosely to refer to any destination for data.
We’re here to share our experience with realtime: we’ll provide a definition and current examples, peer into the future of realtime, and try and shed some light on the eternal realtime vs. real-time vs. real time semantic debate.
-
Pushpin reliable streaming
Jan 22, 2017 • posted by justin
• filed under api, grip, pushpinEarlier this month we discussed the challenges of pushing data reliably. Fanout products such as Pushpin (and Fanout Cloud, which runs Pushpin) do not entirely insulate developers from these challenges, as it is not possible to do so within our scope. However, we recently devised a way to reduce the pain involved.
Realtime APIs usually require receivers to juggle two data sources if they want to receive data reliably. For example, a client might listen for updates using a best-effort streaming API, and recover data using a REST API. So we thought, what if Pushpin could manage these two data sources, such that the client only needs to worry about one?