Pushpin reliable streaming
Jan 22, 2017 • posted by justin  • filed under api, grip, pushpin
• filed under api, grip, pushpin
Earlier this month we discussed the challenges of pushing data reliably. Fanout products such as Pushpin (and Fanout Cloud, which runs Pushpin) do not entirely insulate developers from these challenges, as it is not possible to do so within our scope. However, we recently devised a way to reduce the pain involved.
Realtime APIs usually require receivers to juggle two data sources if they want to receive data reliably. For example, a client might listen for updates using a best-effort streaming API, and recover data using a REST API. So we thought, what if Pushpin could manage these two data sources, such that the client only needs to worry about one?
Pushpin, now with pull
As a proxy server, Pushpin is uniquely positioned to be able to recover data from the backend server on the client’s behalf, and so we implemented a feature to do just that. The backend server provides a “recovery” URL that Pushpin can use to retrieve missing data.
Here’s a diagram of the process:
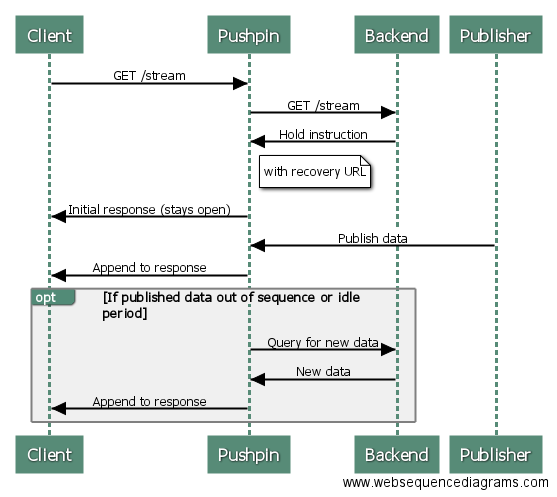
The recovery URL is specified in the Grip-Link response header when returning a hold instruction:
HTTP/1.1 200 OK
Grip-Hold: stream
Grip-Channel: fruit; prev-id=3
Grip-Link: </fruit/?after=3>; rel=next; timeout=120
Later on, if Pushpin detects a gap in the stream of published messages, or if the stream is idle for too long, then it will make a GET request to the recovery URL and dump the response into the stream. For more details, see the documentation.
The end result is that the client always sees a perfect stream without any gaps. What’s interesting about this approach is that the overall architecture is still mostly publish-subscribe, so the backend plumbing remains scalable and easy to reason about. We just moved the recovery logic up one hop from the client to the edge.
Example walkthrough
Below is a simple PHP program (we’ll call it reliable-stream.php) that serves a stream of updates of a JSON blob.
<?php
$data = file_get_contents('data.json');
$id = hash('md5', $data);
$last_id = null;
header('Content-Type: text/plain');
if($_GET['recover'] == 'true') {
// Grip-Last: {channel}; last-id={id}
$grip_last = $_SERVER['HTTP_GRIP_LAST'];
$pos = strpos($grip_last, 'last-id=');
if($pos === FALSE) {
http_response_code(400);
echo "Invalid Grip-Last header.\n";
return;
}
$last_id = substr($grip_last, $pos + 8);
}
header('Grip-Hold: stream');
header('Grip-Channel: reliable-stream; prev-id=' . $id);
header('Grip-Link: </reliable-stream.php?recover=true>; rel=next; timeout=120');
if($last_id != $id) {
echo $data;
}
?>
The program reads the JSON data from a file called data.json and returns the current data upon connect. Let’s assume the content of the file is {"text": "hello"} and make a request to the program, through Pushpin:
$ curl -i http://localhost:7999/reliable-stream.php
We get a response that provides the current data and then hangs open:
HTTP/1.1 200 OK
Server: Apache/2.4.7 (Ubuntu)
X-Powered-By: PHP/5.5.9-1ubuntu4.20
Connection: Transfer-Encoding
Transfer-Encoding: chunked
Content-Type: text/plain
{"text": "hello"}
The program doesn’t do any publishing of its own, which is meant to be handled separately whenever the data.json file is updated. The file’s entire content should be published to the reliable-stream channel, such that each line of the stream provides a whole replacement of the previous data. The update process could go like this:
$ md5sum data.json | cut -d ' ' -f 1 > lastid
$ echo '{"text": "new data"}' > data.json
$ pushpin-publish --id=`md5sum data.json | cut -d ' ' -f 1` \
--prev-id=`cat lastid` reliable-stream @data.json
$ rm lastid
The above sequence of commands would cause additional output to the existing stream:
{"text": "new data"}
You’ll notice the use of IDs when holding and publishing, which is required by Pushpin’s reliability feature. In this example we’re using MD5 hashes of the content as IDs.
Now let’s get into the actual recovery mechanism. The example program specifies /reliable-stream.php?recover=true as the recovery URL. If Pushpin needs to ask for data that may have been missed, it will make a GET request to this URL. The program points back to itself, so it uses some conditional code to only return data if Pushpin needs it:
if($last_id != $id) {
echo $data;
}
In other words, if the MD5 hash known by Pushpin ($last_id) matches the hash of the current data, then don’t return anything. How does the program know the last ID that Pushpin has seen? By reading the Grip-Last header provided by Pushpin in the request. The following block of code does some rudimentary parsing of that header, in order to populate that $last_id variable:
if($_GET['recover'] == 'true') {
// Grip-Last: {channel}; last-id={id}
$grip_last = $_SERVER['HTTP_GRIP_LAST'];
$pos = strpos($grip_last, 'last-id=');
if($pos === FALSE) {
http_response_code(400);
echo "Invalid Grip-Last header.\n";
return;
}
$last_id = substr($grip_last, $pos + 8);
}
To demonstrate how this works, let’s make a request directly to the program (not proxied by Pushpin) so we can see its output. Assume it’s being served on localhost port 8000:
$ curl -i http://localhost:8000/reliable-stream.php
The response:
HTTP/1.1 200 OK
Server: Apache/2.4.7 (Ubuntu)
X-Powered-By: PHP/5.5.9-1ubuntu4.20
Grip-Hold: stream
Grip-Channel: reliable-stream; prev-id=ea405059015cd95c7fac18b4aaeea653
Grip-Link: </reliable-stream.php?recover=true>; rel=next; timeout=120
Content-Length: 18
Content-Type: text/plain
{"text": "hello"}
As you can see, prev-id was set to the current hash. Now, let’s pretend to be Pushpin and set a Grip-Last header in a request, so we can see what comes back:
$ curl -i \
-H "Grip-Last: reliable-stream; last-id=ea405059015cd95c7fac18b4aaeea653" \
http://localhost:8000/reliable-stream.php?recover=true
The response:
HTTP/1.1 200 OK
Server: Apache/2.4.7 (Ubuntu)
X-Powered-By: PHP/5.5.9-1ubuntu4.20
Grip-Hold: stream
Grip-Channel: reliable-stream; prev-id=ea405059015cd95c7fac18b4aaeea653
Grip-Link: </reliable-stream.php?recover=true>; rel=next; timeout=120
Content-Length: 0
Content-Type: text/plain
Empty response body! As expected.
We mentioned earlier that each line of the stream provides a whole replacement of the data, by publishing the entire content of the data.json file whenever it changes. You can see now, how a recovery request would conform to this expectation. If the hashes don’t match, then the entire content is appended to the stream, which is identical to what a successful publish would have looked like.
Note that the reliability feature is not limited to streams of whole data replacements. That’s merely what we’re doing in this example. The feature can work just as well with a stream of deltas.
A better API developer experience
Pushpin’s reliability feature greatly simplifies the client-side:
- The client doesn’t need to worry about sequencing.
- The client doesn’t need to periodically sync with the server.
- As long as a connection exists, the client can assume there are no gaps in the data.
- A single request can be used to receive historical data and reliable pushed data going forward, so there is a single source of truth.
- Resynchronizing after a disconnect only requires a single request.
Most public realtime APIs today don’t work this way, but we think our approach could greatly improve the developer experience around such APIs.
Video
You may enjoy the following video, which covers the same material but shows the reliability feature in action.
Recent posts
-
We've been acquired by Fastly
-
A cloud-native platform for push APIs
-
Vercel and WebSockets
-
Rewriting Pushpin's connection manager in Rust
-
Let's Encrypt for custom domains