Rewriting Pushpin's connection manager in Rust
Aug 11, 2020 • posted by justin  • filed under condure, mongrel2, pushpin, realtime, rust, scalability, websockets, zeromq
• filed under condure, mongrel2, pushpin, realtime, rust, scalability, websockets, zeromq
For over 7 years, Pushpin used Mongrel2 for managing HTTP and WebSocket client connections. Mongrel2 served us well during that time, requiring little maintenance. However, we are now in the process of replacing it with a new project, Condure. In this article we’ll discuss how and why Condure was developed.
Background
Mongrel2 (whose name literally includes the number “2”) is a clever web server project. It uses a messaging protocol for handling client requests. When a client sends an HTTP request, Mongrel2 sends a message over ZeroMQ to a backend handler. Any backend process can respond to the client by sending a message over ZeroMQ back to Mongrel2, specifying the connection ID. This design makes it easy to handle long-lived connections for asynchronously pushing data to clients.
In Zed Shaw’s colorful words:
What makes Mongrel2 special is how it satisfies [web server requirements] in a language agnostic and asynchronous way using a simple messaging protocol [..]. Mongrel2 is also designed to be incredibly easy to automatically manage it as part of your infrastructure. Other web servers do some of these things, but they either do them in a bastardized way or not all of them at once. Plenty of language specific web servers like Node.js and Jetty have asynchronous operation, but they’re not language agnostic. Other web servers will let you talk to any language as a backend, but they insist on using HTTP proxying or FastCGI, which is not friendly to asynchronous operations.
Pushpin not only uses Mongrel2 as a dependency, but in many ways it was inspired by it. Like Mongrel2, Pushpin makes it easy to handle long-lived connections from any language. However, it does this with a channels-based pub/sub layer instead of connection IDs, and it supports HTTP for backend communication (though ZeroMQ is supported too).
Motivation
If Mongrel2 has been working fine, why rewrite it? After all, rewriting is a Thing You Should Never Do. There were several reasons:
- We wanted to support more protocols, such as HTTP/2. Currently, Mongrel2 only supports HTTP/1 and WebSockets.
- We wanted to support multiple CPU cores.
- Mongrel2 is written in C, and we did not want to write a bunch of new C code.
Most of our code is written in C++. I have no trouble writing C and have plenty of experience with it, but in my opinion there aren’t many good reasons to choose it over C++ (or Rust) in the current era. C++ provides more safety with minimal cost, and since it’s a superset there’s nothing to lose. Rust has similar low level capabilities and even more safety.
We considered what the requirements of a rewrite would be as well. A fair amount of Mongrel2’s code is library code, mostly copied/forked from other projects. For example there’s a string library (bstrlib), linked list and hash libraries (kazlib), and a coroutine library (libtask), all embedded in the source tree. Plus, there’s a bunch of code related to configuration management (using SQLite) that we did not really need for Pushpin’s use-case. This meant if we did rewrite it, we wouldn’t necessarily have to rewrite all of it.
Given this, my feeling was that it made sense to attempt to start clean, using either C++ (what we’re familiar with) or Rust (shiny). Regardless of what language we chose, we’d have access to more ergonomic libraries around evented I/O, data collections, etc., which would lessen the pain.
Choosing Rust
Between C++ and Rust, we decided to give Rust a shot. This was motivated primarily by my own interest in using it. I had been playing with the language off and on for a couple of years, while closely monitoring the development of futures and async/await.
I’m impressed with the Rust community’s attention to detail around performance. Of course, C++ code can be just as performant, but many C++ libraries I’ve used in my career haven’t been as obsessive about the little things, like control over heap allocations, as I’ve seen in the Rust standard library and community crates. My sense is that many C++ applications tend to be high performing by virtue of the language being designed during an era when computing resources were more limited, not because applications are necessarily written in the most performant way. On the other hand, Rust feels like what you’d get if kernel developers designed a high level language in the present day.
As we’re a company that provides realtime data infrastructure, performance matters to us, too. Optimizing Pushpin has been on our to-do list, so it seemed worthwhile to consider doing that with Rust.
Architecture
At a high level, the design of Condure looks like this:
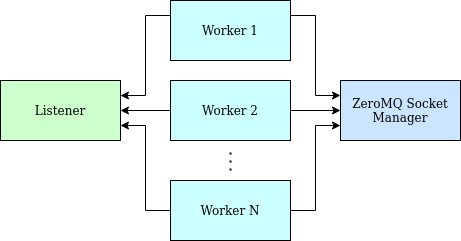
Each box represents a thread. They consist of:
- One listener thread, which binds to TCP ports and accepts connections.
- One ZeroMQ socket manager thread, which handles I/O with ZeroMQ sockets.
- A configurable number of “worker” threads that handle connections. Workers receive connections from the listener and do message I/O with the ZeroMQ socket manager.
Each worker is event driven and able to handle many connections at the same time. If there is only one worker, it will handle all of the connections. Condure is able to take advantage of multiple CPU cores by instantiating multiple workers.
Communication between threads is done using the mpsc module from the Rust standard library. The module supports passing any kind of object around, including complex things like socket objects. This feels natural in Rust since the default behavior of passing an object by value is for it to be moved rather than copied.
To help ensure even distribution of accepted connections, all connections are accepted from the listener thread and then handed over to the workers. Even though there is only one listener thread, it should be sufficient for very high scale, as all it does is call accept() in a loop.
ZeroMQ sockets are intended to only be used from one thread (which rust-zmq enforces by not implementing the Sync trait), so they are set up in the ZeroMQ socket manager thread to be shared by all the workers. As there is only one such thread, the socket manager code is written to be as lightweight as possible. Messages received from workers are simply sent out. Inbound messages are quickly examined to determine which workers to send them to, without doing a full parse.
By keeping the listener and ZeroMQ socket manager threads minimal, the bulk of the application logic can stay in the workers which are scalable. And since the workers communicate with those other threads using channel I/O, the worker code doesn’t have to care about threads and is easy to reason about. There are no mutexes or anything like that in the worker code.
Fair processing and backpressure
Care has been taken to process everything fairly, and to respect backpressure. This helps ensure consistent performance regardless of how many connections are active.
Below are some ways this is done:
- Workers “pull” for connections from the listener. If no workers are pulling, the listener doesn’t call
accept(). - The listener ensures round robin distribution to workers if multiple workers want connections at the same time.
- The ZeroMQ socket manager does round robin reads from workers, if multiple workers are readable at the same time. This way, if one worker tries to send a lot of messages, it will not get in the way of other workers also sending messages.
- If the ZeroMQ socket manager is unable to send outbound messages (because there is no ZeroMQ peer or because the queue is full), it will stop reading from all the workers.
- If multiple connections within a worker need to send a message, but the worker’s channel to the ZeroMQ socket manager is full, each connection is put in a queue and woken once the worker’s channel becomes writable. If a connection sends and then wants to send again, it will go back to the end of the line. This way, if one connection tries to send a lot of messages, it will not get in the way of other connections also sending messages.
- The ZeroMQ messaging protocol used with handlers (ZHTTP) has credits-based flow control. Peers specify how many content bytes they are willing to receive from the other, per-connection. Condure will not read from a connection if it does not have credits from the handler. Likewise, it will only provide additional credits to the handler after it is able to successfully write to a connection.
Event loops
Evented I/O is implemented using mio-based poll loops for each thread type. We are not using async yet, nor Tokio. Despite my relatively good understanding of async Rust, I felt more comfortable beginning with bare poll loops and keeping dependencies minimal. This also established a sort of theoretical maximum performing implementation. Later on we can consider moving to async and adding more libraries and benching the costs as we go.
One thing that surprised me about using mio in real code is I gained a better appreciation for poll loops. Most of my experience with event driven programming is with callback systems (Pushpin uses Qt/C++ with signal/slot callbacks). I must say, poll loops with state machines are much easier to reason about than callback systems. Of course, a coroutine system like async Rust leads to even more readable code, but you can still end up needing to do more than one thing within the same coroutine (for example, needing to select on multiple Rust futures in an async function), in which case you’re back to poll loops. I guess my point is poll loops are not all that terrible.
Optimizations
Since performance was a priority, I decided to challenge myself by implementing the server in a very low level way, using all kinds of optimizations.
Here’s a list of the many optimizations in Condure:
- Minimal heap allocations. Currently, the only runtime allocations are for ZeroMQ message I/O. All the protocol logic and packet parsing/generating is alloc-free. Connection memory is preallocated at startup. I’ve never written this much alloc-free code in my life outside of embedded systems.
- Memory arenas. Some of the preallocated memory is managed as “arenas” using fixed size blocks, allowing the application to do heap-like alloc/free (including reference counted ownership) in fast O(1) time without touching the system allocator.
- Minimal copying. In many cases, packet parsing (such as with
httparse) is done by making slice references to packet content, and keeping around the original packet as the backing data source until the parsed form is no longer needed. - Ring buffers. These are used for the connection buffers, so the bytes don’t always have to be shifted around when there’s I/O.
- Vectored I/O. Basically stuff like
readvandwritev. For example, this means a WebSocket frame can be written using separate header and content parts as input, without having to combine the parts into a new buffer first, and without having to make two write calls to the socket. I’d never done this before and found it pretty unwieldy to get right. - Hierarchical timing wheels. Intuitively you might think to use an ordered map for keeping track of timers, but a timing wheel is even more efficient. I adapted timeout.c by William Ahern and rewrote it in Rust.
- Fast data structures. For example, connections are registered in a
Slabrather than aHashMap. Both offer O(1) access, but a Slab is more efficient if you can accept the limitation of not being able to choose your keys.
Sure, these kinds of things are not unique to Rust and they could have been done in C/C++, but I felt confident doing them in Rust thanks to the guardrails.
Performance
With all of the optimizations, you’d expect Condure to run pretty well. Early observations confirm this to be true! We’ll publish more detailed benchmarks in the future, but here are some standout points:
- We were able to establish 1 million client connections to a single instance.
- We load tested ~16k HTTP requests/second using a single ZeroMQ handler.
- We are seeing a 90% reduction in CPU usage compared to Mongrel2 on our production systems.
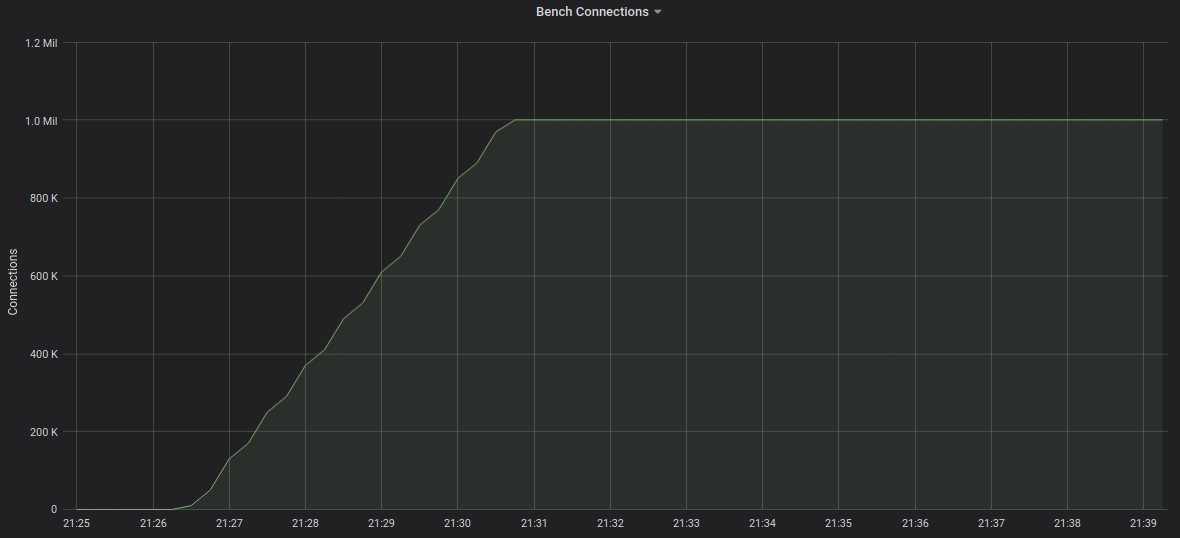
We’re very satisfied with how the project has turned out. Programming in Rust has been challenging but fun, and we’re seeing very real efficiency gains.
Transition
We have been running Condure on Fanout Cloud for the past couple of months. That’s right, we are running Rust in production, in the most critical of paths.
As of Pushpin 1.30.0, Condure can be optionally enabled, however Mongrel2 is still the default. We will eventually make Condure the default, probably after implementing TLS.
Recent posts
-
We've been acquired by Fastly
-
A cloud-native platform for push APIs
-
Vercel and WebSockets
-
Let's Encrypt for custom domains